
みなさんStable Diffusion楽しんでますか?
それともマンネリ気味ですか?
今回紹介するFLUX.1は現状で最高品質の画像が生成できるモデルです!

これだけで気になるでしょ~。
この記事ではFLUX.1の詳細から、画像生成までの手順とコツを紹介します。
- FLUX.1の特徴
- FLUX.1での画像生成手順
- プロンプトのコツ
FLUX.1とは

概要
FLUX.1は、Stable Diffusionを開発したチームのメンバーが立ち上げた、ベンチャー企業「Black Forest Labs」から公開された画像生成AIモデルです。
モデル展開について
FLUX.1は以下3つのモデルが展開されています。
- FLUX.1 Pro
-
Proは名前の通りプロ用で、API経由で使用可能です。
また商用利用可能なモデルで、3つのモデルの中でも最も高品質なモデルだ。 - FLUX.1 dev
-
Proに次ぐ品質で、非商用モデルなんですがモデルが公開されているのでローカルPCで実行することが可能です。
この後、使い方を紹介します。
- FLUX.1 schnell
-
品質は劣るが、なんといっても高速生成が可能なモデルだ。
なんと1~4stepで高画質画像が生成できる!さらに・・・商用利用も可能なんです!
個人的には商用利用、生成速度、品質の面でschnellが流行りそうな予感・・・
FLUX.1の使い方
FLUX.1はWebサービスで使用する他、十分なスペックのPCであればローカルPCでの実行も可能です。
オンラインサービスで試す方法
FLUX.1はwebサービスで画像生成が可能です。
細かいパラメータの設定は出来ませんが、とりあえずどんな画像が生成できるのか試すレベルであれば最適です!
一部、画像生成が有料のものが含まれるのでご注意ください。
- FLUX.1 Pro
- FLUX.1 dev
- FLUX.1 schnell
ローカルPCでの使い方
FLUX.1はご自身のPCにインストールして実行することが可能です。
記事執筆時点ではクライアントツール「ComfyUI」が対応しているので、このツールでの画像生成手順を紹介します。
まだComfyUIをインストールしていない場合は、以下記事を参考にインストールしてみましょう!

インストールしているComfyUIのバージョンが古い場合はFLUX.1が使えない可能性があります。
以下記事を参考に最新バージョンに更新しましょう。
PCスペックについて
FLUX.1 devとschnellをローカルPCで実行する場合は、メインメモリ16GB以上、VRAM12GB以上が必要だといわれています。
私のPC環境はメインメモリ64GB、VRAM12GBですが問題無く画像生成が可能でした。
モデルのインストール
- Unetモデル
-
従来のチェックポイントモデルと同じものと思ってください。
ダウンロードしたファイルは「ComfyUI」→「models」→「unet」に保存します。ダウンロードするには下記リンク先(Hugging face)の「download」をクリックします。
- FP8チェックポイントモデル
-
軽量なFP8モデルを使用したい場合にダウンロードしましょう。
ダウンロードしたファイルは「ComfyUI」→「models」→「checkpoints」に保存します。ダウンロードするには下記リンク先(Hugging face)の「download」をクリックします。
- flux1-dev-fp8.safetensors(必要な場合のみ)
- flux1-schnell-fp8.safetensors(必要な場合のみ)
- VAEの保存
-
下記ファイルを「ComfyUI」→「models」→「vae」に保存します。
ダウンロードするには下記リンク先(Hugging face)の「download」をクリックします。
- テキストエンコーダー
-
下記ファイルを「ComfyUI」→「models」→「clip」に保存します。
ダウンロードするには下記リンク先(Hugging face)の「download」をクリックします。
画像生成手順
以下手順で画像生成可能だ!
今回は公開されているワークフローを使用します。
下記サイトに「Flux Dev」、「Flux Schnell」、「FP8 Flux Dev」、「FP8 Flux Schnell」それぞれのワークフローがあります。
ブラウザ上で該当の画像を起動中のComfyUI上にドラッグ&ドロップすることでワークフローを開くことが可能です。
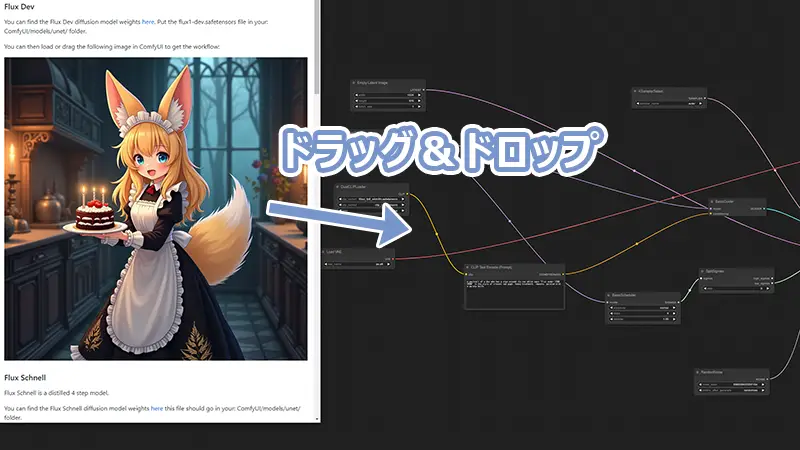
画像(png)をダウンロードし、画像をドラッグ&ドロップすることでもワークフローを開くことが可能です。
これならいつでもワークフローを開くことが可能です。
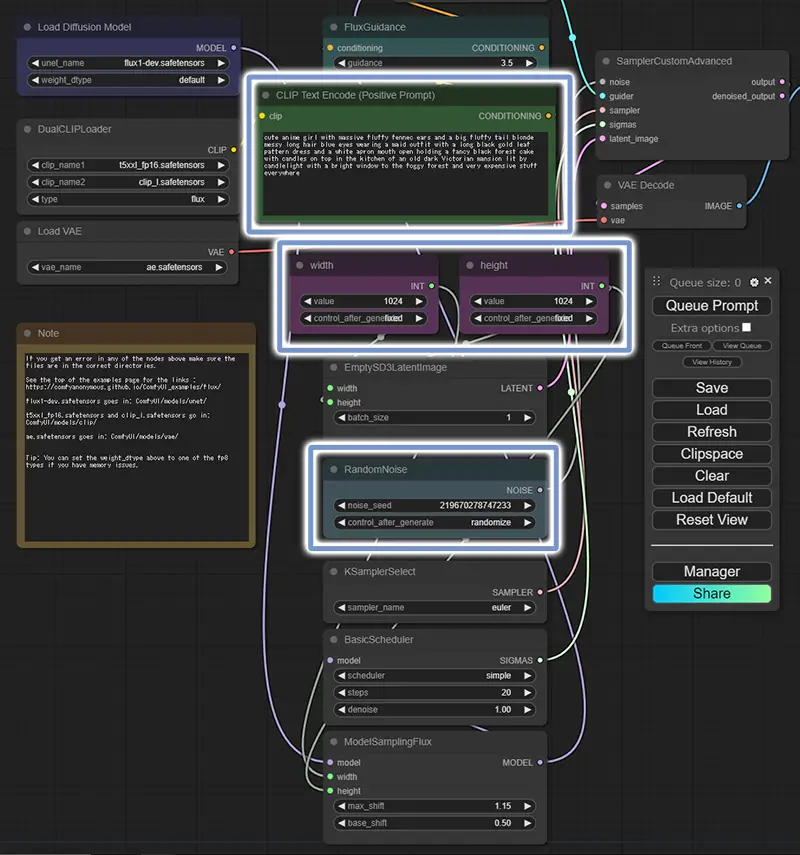
各ワークフローで使用するモデルの一覧を確認する
- Flux Dev
-

- flux1-dev.safetensors
- ae.safetensors
- clip_l.safetensors
- t5xxl_fp16.safetensors もしくは t5xxl_fp8_e4m3fn.safetensors
- Flux Schnell
-
- flux1-schnell.safetensors
- ae.safetensors
- clip_l.safetensors
- t5xxl_fp16.safetensors もしくは t5xxl_fp8_e4m3fn.safetensors
- FP8 Flux Dev
-
- flux1-dev-fp8.safetensors
- FP8 Flux Schnell
-
- flux1-schnell-fp8.safetensors




またcivitai上にもVRAM12GB以下用のワークフローが公開されています。
以下ページの画像をクリックして、表示された画像(png)を起動中のComfyUI上にドラッグ&ドロップすることで、ワークフローを開くことが可能です。
上記のワークフローでもVRAM12GBで生成できたので、あまり必要性は感じませんでした。
通常は必要ありません。
サブフォルダに保存するなど、デフォルトフォルダから変更した場合は各モデルを選択し直してください。
プロンプト、解像度の変更がメインとなり、seed値等ももちろん変更可能です。
ワークフローで調整するパラメータの場所を確認する
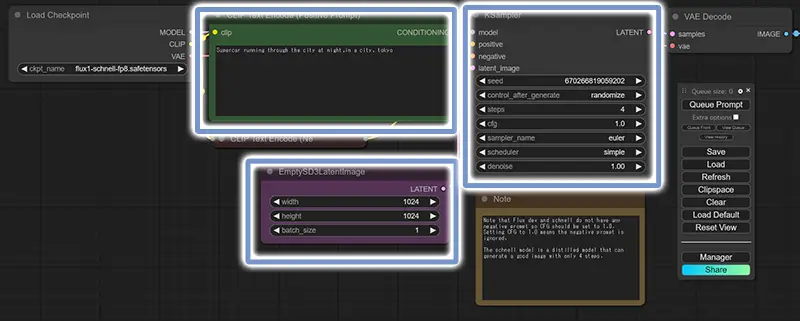
「Queue Prompt」をクリックすると画像生成開始です。
生成完了までしばらく待ちましょう。
FLUX.1で画像生成した結果・プロンプト紹介
各モデルで色々なプロンプトをテストしました。
テストした限り、FLUX.1は単語単位のプロンプトよりも、自然言語による長文に対する追従性が高かったです。
※リソース使用状況・生成時間はPC環境が大きく影響します、掲載データは参考までに~
DevとSchnellモデルの比較


使用したプロンプトを確認する
Japanese woman doing peace sign,evening,in a park生成時のリソース状況・生成時間を確認する
- Dev
-
1024×1024 20step
VRAM:11.5gb
生成時間:約56sec - Schnell
-
1024×1024 20step
VRAM:11.5gb
生成時間:約19sec
Schnellはステップ数が少ないのでかなり高速に生成できました。
ただ品質に関してはDevが勝っています。
当然の結果といえば当然ですが。
手を狙って生成しましたが、従来のStableDiffusionモデルと比較すると精度は上がった印象です。
ただ、完璧ではなく指の本数を間違えたりと、手が苦手なことは変わりません。
DevモデルとFP8 Devモデルの比較


使用したプロンプトを確認する
A beautiful woman holding a placard that says "test Flux", sunset, in a street生成時のリソース状況・生成時間を確認する
- Dev
-
1024×1024 20step
VRAM:11.5gb
生成時間:約56sec - FP8 Dev
-
1024×1024 20step
VRAM:11.5gb
生成時間:約72sec
非常に綺麗で、文字の再現についても完璧です!
FP8モデルと比較すると画質については同等なので、FP8モデルの優位性はストレージ容量だけのように感じました。
SchnellモデルとFP8 Schnellモデルの比較


使用したプロンプトを確認する
Supercar running through the city at night,in a city, tokyo生成時のリソース状況・生成時間を確認する
- Schnell
-
1024×1024 4step
VRAM:11.5gb
生成時間:約15sec - FP8 Schnell
-
1024×1024 4step
VRAM:11.5gb
生成時間:約18sec
フォトリアル系でオブジェクトの写真を生成しました。
人物以外についても高品質です!
車や背景は綺麗ですが、車の走っている位置は若干怪しいですね(笑)
こちらもDevモデルと同様に、通常モデルとFP8の品質は同等で、生成リソース状況に差は無い状態でした。
アニメ、イラスト調画像の確認

使用したプロンプトを確認する
Illustration,anime,Beautiful woman standing with her arms crossed, cyberpunk, in a city日本風のアニメやイラストを想像すると残念な結果ですね。
品質はそれなりですが、これじゃない感があります。
単語単位プロンプトの確認

使用したプロンプトを確認する
photos, Portrait, 1 japanese girl, 25yo, black long hair, wind最初にお伝えした通り、単語単位でプロンプトを記載すると生成画像がブレます。
(プロンプトの追従性が落ちる)
なのでプロンプトについては、長文による記載をおすすめします。
Schnellモデルで4step超に設定
Schnellモデルは通常4stepで生成しますが、ステップ数を多くするとその分高品質になります。
まぁその分、高速生成のメリットが少なくなるけどね。
以下の画像は12stepで生成しています。
12stepまで上げると、Devモデルと見分けがつかないほど高画質になるし、高速生成の恩恵も受けられます。

使用したプロンプトを確認する
Photo of a bearded man wearing futuristic armor,cinematicNSFW画像生成について
FLUX.1はNSFW系でガードがかけられているのか、プロンプトで指定しても狙った画像が生成できません。
紳士の方は残念ですが、今しばらくファインチューニングモデルを待ちましょう!
FLUX.1を使用する上での注意事項
FLUX.1で使用するモデルの容量がかなり多いので、インストールするストレージの容量はもちろん、NVMe規格等の高速なストレージに保存することをおすすめします。
スピードの遅いストレージにモデルを保存すると、ロードするだけで数分要する場合があります。
容量の多いモデルは以下の通りです。
- flux1-dev.safetensors 23.8GB
- flux1-dev-fp8.safetensors 17.2GB
- flux1-schnell.safetensors 23.8GB
- flux1-schnell-fp8.safetensors 17.2GB
- t5xxl_fp16.safetensors 9.79GB
- t5xxl_fp8_e4m3fn.safetensors 4.89GB
以下記事で画像生成AIにおすすめのストレージを紹介しているので、ご参考ください。

まとめ
今回はFLUX.1を使用する方法を紹介しました。
FLUX.1は現状、最高クオリティの画像を生成できますが、モデルデータが重い点がデメリットですね。
今後は軽量化・最適化されたモデルはもちろんファインチューニングモデルも展開されると考えられます。
特にイラスト系やNSFWは不得意なので、そのあたりがクリアになると一気に普及しそうな予感がします。


















コメント