
stability aiの新モデル「Stable Diffusion 3.5」が公開されました!
この記事ではローカルPCでStable Diffusion 3.5とComfyUI を使って、画像生成する手順を紹介します。
Stable Diffusion 3.5 とは?
2024年10月に公開されたstability aiの最新画像生成モデルです。
本日は、Stable Diffusion 3.5 をご紹介します。このオープン リリースには、Stable Diffusion 3.5 Large や Stable Diffusion 3.5 Large Turbo など、複数のモデル バリアントが含まれています。さらに、Stable Diffusion 3.5 Medium は 10 月 29 日にリリースされる予定です。
これらのモデルはサイズに応じて高度にカスタマイズ可能で、コンシューマー ハードウェア上で実行され、許容度の高いStability AI Community Licenseに基づいて商用および非商用の両方で無料で使用できます。
stability ai
2024年に公開されたStable Diffusion 3は、はっきりいって失敗作でした。
わくわくしていたみなさんも、がっかりしたことでしょう・・・

その後、Stable Diffusionを開発したメンバーがリリースしたFLUX.1は期待通りの性能で、盛り上がっています。
このときStable Diffusion 3は完全に負けたといってよいでしょう。

そして、stability aiはStable Diffusion 3の失敗を挽回するべく、「Stable Diffusion 3.5」を公開したわけです。

どこまで品質が上がったのか気になるよね。
Stable Diffusion 3.5は、前バージョンと同様に3つのモデルで展開されます。
それぞれ以下のような特徴があります。
Stable Diffusion 3.5 各モデルの特徴
- Stable Diffusion 3.5 Large
-
80億のパラメータで基本となる高品質なモデルです。
- Stable Diffusion 3.5 Large Turbo
-
Largeの蒸留版で4stepの高速生成でも、高品質な画像が生成できるモデルです。
- Stable Diffusion 3.5 Medium
-
26億のパラメータで、カスタマイズ性と画質を両立させたモデルです。
個人用PCで実行できるよう軽量なモデルとなっています。
商用利用について
個人や企業でライセンスが異なるようです。
詳細は以下の通りです。
非営利目的の場合は無料:個人および組織は、科学研究を含む非営利目的であれば、モデルを無料で使用できます。
商用利用は無料(年間収益が 100 万ドルまで):スタートアップ企業、中小企業、クリエイターは、年間総収益が 100 万ドル未満であれば、無料でこのモデルを商用目的で使用できます。
stability ai
以上のことから、個人の場合は年間収益が100万ドルを超えることは無いと考えられるので、
問題無く商用利用可能と判断できますね!
ComfyUIでのインストール手順
ここからは、Stable Diffusion 3.5で使用するモデル等のインストール方法を紹介します。
記事執筆時点ではComfyUIがStable Diffusion 3.5にネイティブ対応しています
ComfyUIのインストールとアップデート
ComfyUIのインストールが済んでいない方は、下記の記事を参考にインストールしましょう。

インストール済みの方は、ComfyUIを最新バージョンにアップデートしましょう。
アップデート手順については以下の記事で紹介しています。
Stable Diffusion 3.5モデルのインストール方法
Stable Diffusion 3.5は複数のモデルで展開されており、PCのスペックにより使用するモデルを選択します。
PCスペックに不安のある方は低RAM環境のモデルを使用しましょう。
32GB以上のRAMを搭載している場合には、通常環境がおすすめです
通常環境(fp16)
- チェックポイントモデル
-
models \ checkpoint フォルダーに保存する
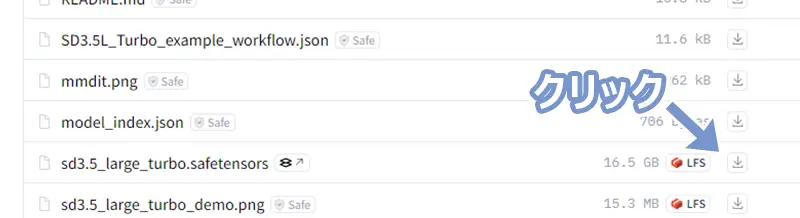
- stable-diffusion-3.5-large(sd3.5_large.safetensorsを保存する)
- stable-diffusion-3.5-large-turbo(sd3.5_large_turbo.safetensorsを保存する)

- テキストエンコーダー
-
models \ clip フォルダーに保存する

低RAM環境(fp8)
- チェックポイントモデル
-
models\checkpoint フォルダーに保存する
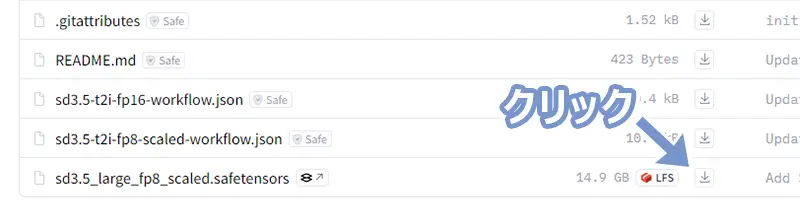
- stable-diffusion-3.5-fp8(sd3.5_large_fp8_scaled.safetensorsを保存する)
- テキストエンコーダー
-
models/clip フォルダーに保存する
t5xxl*.safetensorsはどちらか一つで問題ありません(scaledは実験的モデル)
またclip_g,clip_lは上記通常環境で紹介したモデルと同様です
ComfyUIでの画像生成手順
Hugging Faceのページからワークフローをダウンロードします。
ダウンロードしたワークフローは任意のフォルダーに保存します。
- sd3.5-t2i-fp16-workflow.json(通常環境(fp16)用ワークフロー)
- sd3.5-t2i-fp8-scaled-workflow.json(低RAM環境(fp8)用ワークフロー)
ワークフローをダウンロードしたら、ComfyUIのコントロールパネル内の「Load」をクリックして開きます。
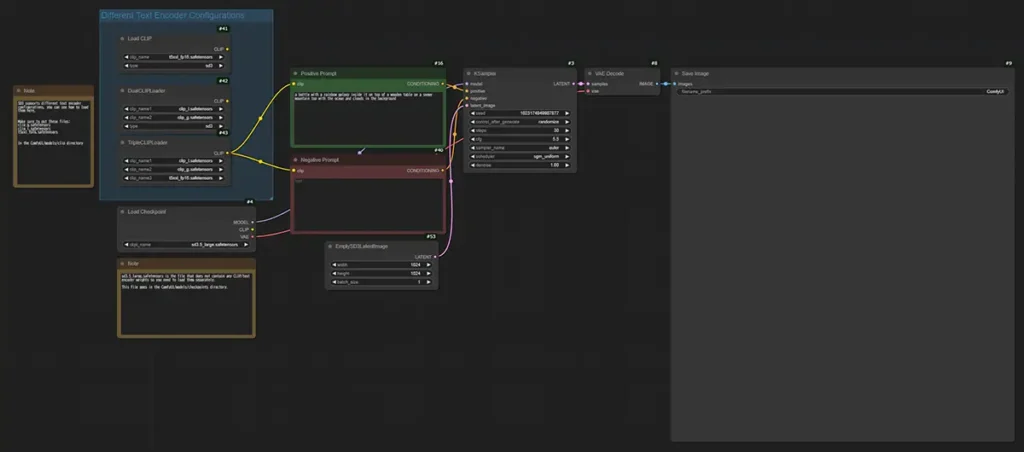
- モデルの選択
-
テキストエンコーダーは指定したフォルダに保存するだけで問題ありませんが、低RAM用のfp8モデルは選択する必要があるので注意してください。
ワークフローの左下のノードでチェックポイントモデルを選択します。
- プロンプトの設定
-
ワークフローの真ん中あたりのノードでプロンプトを設定します。
Negative Prompt(ネガティブプロンプト)も設定可能ですが、Stable Diffusion 3.5では特に必要性を感じません。 - 解像度の設定
-
ワークフローの真ん中、下部のノードで画像解像度の設定が可能です。
解像度は64の倍数で設定しましょう。
64の倍数から外れると画像の品質が低下します。 - ステップ数、サンプラーの設定
-
ワークフローの真ん中右のノードで設定が可能です。
通常モデルはstep数30~50、cfg4.5~5.5くらいがおすすめです。
Turboモデルを使用する場合は、step数4、cfg1の設定がおすすめです。
設定が完了したらコントロールパネル内の「Queue Prompt」をクリックして画像生成を開始しましょう!
Stable Diffusion 3.5で生成したサンプル画像
fp16、fp8、Turboモデルで各サンプル画像を生成しました。
FLUX.1で生成した画像も掲載するので、使えるレベルなのか確認していきましょう!
パネルを持った女性




使用したプロンプトを確認する
A photorealistic 4K image of a japanese girls, A Japanese girls holding a card that says "Test SD3.5"アニメ調女性




使用したプロンプトを確認する
Illustration,anime,Beautiful woman standing with her arms crossed, cyberpunk, in a city都市を走るスーパーカー




使用したプロンプトを確認する
Supercar running through the city at night,in a city, tokyo草原に寝転ぶ女性



使用したプロンプトを確認する
A photorealistic 4K image of young woman lying on a meadowひまわりの種を食べるハムスター



使用したプロンプトを確認する
Hamster eating sunflower seedsいかがでしょうか。
あくまでファーストインプレッションですが、私的にはFLUX.1の方が優れているように感じます・・・
fp8、turboモデルの画像の方が魅力的に見えます。
FLUX.1のほうが自然でリアルに感じるのは私だけでしょうか?
後発だったのでFLUX.1を抜いていく勢いがあるのかと思いましたが、少し残念です。
すでにFLUX.1はファインチューンモデルも展開されているので、Stable Diffusion 3.5が今後どうなるのか気になるよね。
まとめ
今回はComfyUIでStable Diffusion 3.5を使用する方法を紹介しました。
FLUX.1と肩を張れるかというと微妙に感じますね・・・
LargeモデルはPCスペックが要求されますが、Mediumモデルは扱いやすいし品質も高いので、どちらかというとMediumモデルがおすすめです。
Stable Diffusion 3.5 Mediumの使い方については以下の記事で紹介しています。













コメント